
台積電 A16 技術深度解析:GAA、背面供電與 3D 整合的埃米革命
在人工智慧 (AI) 和高效能運算 (HPC) 永無止境的計算需求驅動下,半導體產業正處於一個關鍵的轉捩點;這種對處理能力的無盡渴求,使得傳統基於簡單幾何微縮的摩爾定律節奏已顯得力不從心;為此,產業正邁向埃米 (Angstrom) 時代,這是一個新的典範,其中效能、功耗和面積 (PPA) 的提升不再僅僅透過縮小電晶體尺寸來實現,而是透過對晶片本身進行根本性的架構重塑。
引領這場變革的先鋒是台灣積體電路製造股份有限公司 (TSMC),其 A16 製程技術預計於 2026 年下半年投入生產,代表著一項里程碑式的成就;A16 並非一個漸進式的節點,而是一個體現了「3D 製程技術」三重定義的整體平台,本報告將透過剖析其三大核心支柱,對此平台進行深入的技術介紹:
- 3D 電晶體架構:
從準平面的鰭式場效電晶體 (FinFET) 到真正的三維環繞式閘極 (GAA) 奈米片電晶體的根本性轉變,這種元件物理學的演進對於在原子尺度上控制電子流至關重要,從而實現卓越的效能和功耗效率。 - 3D 電力架構:
引入超級電軌 (Super Power Rail, SPR),這是台積電對背面供電網路 (BSPDN) 的實作,這項技術為晶片的電網增加了垂直維度,將其與訊號網路分離,以緩解困擾先進設計的互連瓶頸。 - 3D 系統整合:
將 A16 定位為台積電全面 3DFabric 產品組合中的頂級邏輯技術,基於 A16 的晶片粒 (chiplets) 重點在透過先進封裝技術,如基板上晶圓上晶片封裝 (CoWoS) 和系統整合晶片 (SoIC),整合到複雜的異質系統中,創造出超越單一裸晶片能力的強大系統。
本文將深入探討上述每一個面向,它將分析 GAA 和 BSPDN 架構的底層物理、製造挑戰及效能影響;此外,本文亦把 A16 置於更廣泛的 3D 整合生態系統中進行脈絡分析,檢視其對電子設計自動化 (EDA) 和競爭格局的影響,並對埃米時代半導體技術的未來提供前瞻性觀點。
電晶體革命 - 環繞式閘極 (GAA) 奈米片架構
向 A16 節點的過渡建立在電晶體本身的根本性變革之上,從長期服役的鰭式場效電晶體 (FinFET) 轉向環繞式閘極 (GAA) 奈米片架構,不僅僅是一個演進步驟,而是將微縮推進至埃米領域的必要革命。
從 FinFET 到 GAA:物理上的必然性
從 22 奈米到 5 奈米節點,為半導體製造帶來革命性變革的 FinFET 架構,正遭遇其物理極限,在 FinFET 中,閘極從三面包覆矽通道,雖然這比舊的平面電晶體在靜電控制上有顯著改進,但在 3 奈米及更先進的節點上則顯得不足;其主要限制包括對短通道效應的控制能力下降,導致漏電流增加,以及其剛性的通道幾何形狀(「鰭片」)限制了調整電晶體效能的能力。
 FinFET(鰭式場效電晶體)架構示意圖,其中閘極(Gate)從三面包圍著稱為「鰭片」(Fin)的矽通道。(圖片來源:TSMC)
FinFET(鰭式場效電晶體)架構示意圖,其中閘極(Gate)從三面包圍著稱為「鰭片」(Fin)的矽通道。(圖片來源:TSMC)
GAA 架構直接解決了這些缺點,顧名思義,GAA 電晶體中的閘極材料完全從四面包覆通道,這種 360 度的閘極控制提供了卓越的靜電完整性,大幅減少漏電流,並允許電晶體在更低的電壓下高效運作,這使得 GAA 成為 FinFET 不可或缺的繼任者,以持續改進 PPA。台積電的 A16 遵循其 2 奈米 (N2) 家族所設定的路徑,建立在這種先進的奈米片 GAA 結構之上。
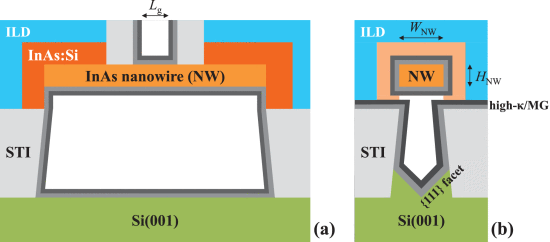
這張環繞式閘極 (Gate-All-Around, GAA) 電晶體示意圖,完美詮釋了其超越前代技術的關鍵;圖 (a) 為縱向視圖,而核心的圖 (b) 橫截面則清楚展示,閘極 (Gate) 材料如何從四面八方完整地「環繞」住半導體通道 (Channel);正是這種全方位的包裹結構,實現了優越的「360度閘極控制」,能更有效地啟閉電流、大幅減少漏電,為新一代晶片帶來更強的效能與更低的功耗。(圖片來源: IEEE Xplore)
台積電的奈米片實作
台積電對 GAA 的具體實作,採用了垂直堆疊的水平矽「奈米片」作為通道,這種垂直堆疊允許在相同的佈局面積內獲得更大的總通道寬度,從而增加電晶體的驅動電流和效能。
台積電 GAA 平台的一個關鍵特性,由 A16 從 N2 製程家族繼承而來,是 NanoFlex;NanoFlex 為設計師提供了前所未有的靈活性,與鰭片高度固定的 FinFET 不同,NanoFlex 允許設計師在同一個設計區塊內調整奈米片的寬度,這使得能夠創建具有不同特性的標準單元:「矮」單元使用窄片以實現最大密度和功耗效率,「高」單元使用寬片以實現最大效能和驅動電流。設計師可以混合搭配這些單元,精確地優化晶片的不同部分,以達到理想的 PPA 平衡。
此能力代表了設計與技術協同優化 (DTCO) 的重大飛躍,晶片架構和製程技術不再是孤立開發的;相反地,設計師在物理層面獲得了強大的新控制手段;A16 繼承了 N2 家族已建立的 NanoFlex 架構,這是一個關鍵優勢,因為它簡化了客戶的遷移路徑,並允許他們重複使用為 N2 平台開發的智慧財產權 (IP) 和設計方法。
GAA 的製造與設計挑戰
GAA 奈米片電晶體的製造比 FinFET 複雜一個數量級,這為現有晶圓代工廠鞏固市場領導地位創造了巨大的進入門檻,其製程流程涉及一系列需要原子級精度的步驟,它始於交替的矽 (Si) 和矽鍺 (SiGe) 層的超晶格磊晶生長,然後對這個堆疊進行圖案化和蝕刻以形成鰭片,在一個稱為「通道釋放」的關鍵步驟中,選擇性地蝕刻掉 SiGe 層,留下將形成電晶體通道的懸浮矽奈米片。最後, 精心地沉積高介電常數 (high-k) 介電質和金屬閘極,以包覆這些懸浮的片層。
這個複雜的過程帶來了重大的量測和變異性挑戰,任何在蝕刻深度、表面粗糙度(稱為線邊緣粗糙度 LER 和線寬粗糙度 LWR)或閘極金屬沉積上的微小偏差,都可能導致電晶體效能的巨大變化,並最終影響製造良率,這需要新的、高度先進的量測技術和強大的可製造性設計 (DFM) 方法,並由支援奈米片的 EDA 工具和新的製程設計套件 (PDK) 來管理複雜的佈局規則。
奈米片時代的可靠性
轉向 GAA 帶來了新的可靠性問題,這些問題必須在 A16 中得到管理,雖然 GAA 結構繼承了 FinFET 已知的退化機制,如偏壓溫度不穩定性 (BTI) 和熱載子注入 (HCI),但它們也引入了其設計獨有的新弱點。
其中一個最關鍵的新故障模式是內間隙壁隨時間介電質崩潰 (inner spacer Time-Dependent Dielectric Breakdown, TDDB),內間隙壁是一種將閘極與源極/汲極區域隔離的介電材料,其獨特的月牙形輪廓以及難以控制其厚度和均勻性,使其成為電性崩潰的潛在弱點。
此外,GAA 電晶體的可靠性對其物理幾何形狀高度敏感,奈米片的厚度、寬度和邊角輪廓等因素直接影響電場和自熱效應,進而影響 BTI 和 HCI 的退化,奈米片的堆疊特性也可能導致熱侷限性增加,與 FinFET 相比,加劇了自熱效應。
另一個挑戰來自與背面供電的協同作用,為 BSPDN(將在下文討論)所需的矽基板極度減薄,減少了可用於散熱的矽體積,這對靜電放電 (ESD) 保護元件構成了重大挑戰,因為這些元件依賴此體積來安全處理大電流。
|
指標 |
FinFET |
GAA (奈米片) |
|
閘極控制 |
部分 (3面) |
完全 (4面) |
|
短通道控制 |
中等 |
優異 |
|
效能調整 |
剛性鰭片寬度 |
可調片寬 (NanoFlex) |
|
垂直堆疊性 |
否 |
是 (可多片堆疊) |
|
主要可靠性問題 |
寄生電容、鰭片變異性 |
內間隙壁 TDDB、熱侷限 |
|
主要優勢 |
成熟度高、生態系統完善 |
優異的靜電特性、增強的 DTCO |
重塑電力架構 - 超級電軌 (Super Power Rail) (BSPDN) 典範
當 GAA 奈米片電晶體重新定義了 A16 的基本建構單元時,超級電軌則徹底改變了這數十億電晶體的供電方式,引入背面供電網路 (BSPDN) 可說是數十年來邏輯晶片設計中最重要的架構轉變,將電網移入了第三維度。
互連瓶頸與 BSPDN 的理由
在傳統的晶片設計中,複雜的訊號佈線和穩健的供電網格都位於晶圓的正面,堆疊在稱為後段製程 (BEOL) 的金屬層中,隨著電晶體縮小且密度增加,這兩個網路越來越多地爭奪有限的佈線空間,這造成了一種「交通堵塞」,導致了幾個關鍵問題:更高的佈線電阻,浪費電力;顯著的電壓 (IR) 降,可能損害電晶體的效能和穩定性;以及增加的訊號串擾和干擾。
BSPDN 透過完全分離電力和訊號網路,為這個問題提供了一個優雅的解決方案,主要的電力分配網路被移到矽晶圓的背面,這個空間傳統上僅作為被動載體,這釋放了整個正面的 BEOL 堆疊用於訊號佈線,緩解了擁塞,並實現了更乾淨、更快、更高效的晶片設計。
台積電的超級電軌 (SPR) 實作
台積電對 BSPDN 的實作,品牌為超級電軌 (Super Power Rail, SPR),是 A16 製程的基石。該公司的方案被認為是業界最先進和有效的方案之一,SPR 架構透過專門的、高導電性的接觸點,將背面供電網路直接連接到每個奈米片電晶體的源極和汲極端子,這種直接連接最大限度地縮短了電子必須行進的路徑,顯著降低了電阻和 IR 降,同時最大化了電源完整性。
這種架構提供了幾個深遠的好處,透過將正面佈線資源專門用於訊號,它允許更密集和更複雜的邏輯設計,直接有助於 A16 的晶片密度提升,增強的電力傳輸使 A16 成為最苛刻應用的理想技術,特別是 HPC 和 AI 加速器,它們具有極其複雜的訊號路徑和密集、耗電的計算區塊。
這種策略性的實作是一個關鍵的差異化因素,雖然英特爾在其 18A 節點上與其 RibbonFET GAA 電晶體同時推出其 PowerVia BSPDN 技術,但台積電做出了深思熟慮的選擇,以降低其技術藍圖的風險;台積電首先在 N2 和 N2P 節點上使其 GAA 技術成熟,然後才在 A16 上增加 BSPDN 的巨大複雜性;這種保守的、分階段的方法,隔離了每項革命性技術的製造和良率風險,為客戶在 2026 年提供了一個分層的產品組合:N2P 提供了一個風險較低、更具成本效益的 GAA 解決方案,而 A16 則為那些能夠證明其增加的成本和複雜性是合理的應用提供了帶有 SPR 的終極效能。
BSPDN 的製造障礙
超級電軌的實施帶來了許多艱鉅的製造挑戰,需要在製造廠中採用全新的製程和工具,其製程流程是材料科學和機械工程的奇蹟。
首先,電晶體像往常一樣在晶圓的正面製造,然後,在一個關鍵步驟中,這個活性晶圓被翻轉並使用先進的混合鍵合技術面朝下鍵合到一個空白的載體晶圓上;然後,原始晶圓進行極端的背面減薄,將其研磨和拋光至僅幾微米的厚度,以暴露活性電晶體層的底部;之後,從背面蝕刻奈米級矽穿孔 (nTSV),以創建通往電晶體的路徑。最後,在新生產的背面上沉積並圖案化背面金屬堆疊——即超級電軌本身 ;這些步驟中的每一步都帶來了獨特的挑戰:
晶圓減薄與翹曲
在不引入缺陷或顯著翹曲的情況下,實現均勻、超薄的晶圓是極其困難的,鍵合過程本身就會引起應力和變形,必須小心管理。
正反面對準
將背面特徵與正面奈米級的電晶體以完美的精度對準,是一個全新且關鍵的製程控制挑戰。
熱管理
BSPDN 的引入從根本上改變了晶片的熱景觀,在傳統晶片中,熱量從電晶體向上通過矽傳導到散熱器,有了 SPR,BEOL 的金屬和介電層現在位於活性元件和主要冷卻路徑之間,起到了熱絕緣體的作用,這需要新的熱管理解決方案,並要求熱分析成為首要的設計考量;佈局和繞線工具現在必須從設計過程的一開始就共同優化熱完整性,使得多物理場模擬成為 EDA 流程中不可或缺的一部分。
機械應力
在晶圓背面增加新材料和製程,會對精密的奈米片電晶體產生顯著的機械應力;這種應力會改變它們的電氣特性並影響長期可靠性,需要仔細的建模和緩解。
協同增益 - A16 效能、功耗與面積 (PPA) 分析
GAA 奈米片電晶體與超級電軌背面供電網路的結合,產生了協同的 PPA 增益,這定義了 A16 節點的價值主張,這些改進雖然顯著,但也反映了一個更廣泛的產業趨勢,即架構創新而非純粹的幾何微縮,成為進步的主要驅動力。
量化飛躍:A16 vs. N2P
台積電已正式詳細說明了 A16 相對於其 N2P 製程的預期 PPA 改進,N2P 是 N2 節點的增強版,不具備背面供電功能,這些數據突顯了 A16 對 HPC 應用的專注:
- 效能:
與 N2P 相比,A16 在相同的工作電壓 (Vdd) 下,預計可提供 8% 至 10% 的速度提升。 - 功耗:
或者,在相同速度下,A16 可提供 15% 至 20% 的功耗降低。 - 密度:
對於資料中心和 HPC 產品,A16 提供了高達 1.10 倍的晶片密度提升(7% 至 10% 的增益)。
值得注意的是,A16 是一項獨特的技術,而不僅僅是增加了功能的 N2P,台積電已確認,除了超級電軌外,A16 還包含了電晶體層級的改進,使其成為一個真正的後繼節點;雖然這些 PPA 增益是實質性的,但與 FinFET 時代高峰期所見的世代飛躍相比,它們更為溫和;這突顯了產業的轉變:隨著純粹電晶體微縮的效益減弱,新節點的價值越來越多地來自於像 BSPDN 這樣的架構突破,這些突破透過改善電力傳輸效率和緩解佈線擁塞來釋放效能。
經濟方程式:成本 vs. 效益
A16 的先進功能伴隨著高昂的價格,產業報告指出,A16 製程的每片晶圓成本可能高達 45,000 美元,這與傳聞中 N2 晶圓的 30,000 美元和 N3 晶圓約 20,000 美元的價格相比,是一個巨大的增長;這個溢價直接歸因於實施超級電軌 BSPDN 技術所需的巨大複雜性和額外的製造步驟,包括晶圓鍵合、減薄和背面金屬化。
這種高成本結構對市場產生了深遠的影響,A16 將主要被一群開發大型、複雜和高利潤處理器的特定客戶所採用,主要目標市場是 AI 和 HPC,在這些領域,每瓦效能和密度的提升提供了令人信服的總擁有成本 (TCO),證明了高昂的初始投資是合理的,對更強大 AI 加速器的無盡需求是使 A16 可行的關鍵經濟驅動力。
這一趨勢將加速半導體市場的兩極分化,雖然少數超大規模數據中心和 AI 領導者如蘋果、輝達和 OpenAI 將利用 A16 的絕對領先優勢,但更廣泛的市場將越來越依賴更具成本效益的解決方案,為此,台積電正在積極開發一系列不同性價比的節點組合,一個典型的例子是 N4C 製程,這是 4 奈米家族的延伸,專為「價值級」產品提供 8.5% 的裸晶成本降低而設計,這一策略使台積電能夠服務從超高端到對成本敏感的整個市場。
「埃米」命名法
「A16」製程的命名本身就是一個重要的聲明,「A」正式代表埃米 (Angstrom),「16」則意味著 1.6 奈米級的技術,標誌著台積電正式進入半導體製造的埃米時代,這也是一個明確的策略性行銷舉措;透過將其 2026 年的技術命名為「A16」,台積電正直接將其與競爭對手英特爾的「18A」節點對位,巧妙地暗示在持續的製程領導地位之爭中具有世代優勢。
製程節點 |
電晶體類型 |
供電方式 |
相對於 N3E 的效能 |
相對於 N3E 的功耗 |
相對於 N3E 的密度 |
|
N3E |
FinFET |
正面 |
基準 |
基準 |
基準 |
|
N2 |
GAA 奈米片 |
正面 |
+10% 至 15% |
-25% 至 -30% |
~1.15x |
|
N2P |
GAA 奈米片 |
正面 |
~+18% |
~-36% |
~1.15x |
|
A16 |
GAA 奈米片 |
背面 (SPR) |
~+28% 至 30% |
~-46% 至 -49% |
~1.23x 至 1.27x |
超越節點 - 3D 整合生態系統
要完全理解 A16 的重要性,不能將其視為一項獨立的技術,而應視其為一個更大、更複雜系統的運算核心,A16 的「3D 製程技術」的第三個維度是其原生整合到一個複雜的 3D-IC 封裝平台生態系統中,這種系統級的整合是台積電應對建造需要前所未有記憶體頻寬和互連密度的大規模 AI 系統挑戰的答案。
A16 的主要角色並非被製造成一個巨大的單晶片系統單晶片 (SoC),因為除了極少數的利基應用外,其成本將高得令人卻步;相反地,A16 被設計成異質系統中的「高階運算晶片粒」,這種晶片粒策略讓設計師可以將昂貴的 A16 製程專門用於需要其尖端效能的核心邏輯,而將較舊、更具成本效益的製程節點用於其他功能,如 I/O、記憶體控制器和類比介面;這種將單晶片設計分解為多個晶片粒的方式,大大降低了整體系統成本和設計複雜性,而其成功完全取決於將這些晶片粒拼接在一起的先進封裝技術。
先進封裝平台:CoWoS 和 SoIC
台積電的 3DFabric 產品組合為建構這些異質系統提供了必要的技術:
CoWoS (基板上晶圓上晶片封裝)
這是台積電成熟且廣泛採用的 2.5D 封裝技術,它允許多個邏輯晶片粒和高頻寬記憶體 (HBM) 堆疊並排置於一個大型矽中介層上,該中介層提供了它們之間的高密度佈線,基於 A16 的運算晶片粒將使用 CoWoS 進行整合,以連接到下一代 AI 加速器所需的大量 HBM4 記憶體,台積電的藍圖包括大型 CoWoS 封裝,目標是在 2027 年完成一個具有 9 個光罩尺寸中介層、採用 SoIC 堆疊晶片粒和 12 個 HBM4 堆疊的封裝的驗證。
SoIC (系統整合晶片)
這是台積電真正的 3D 堆疊技術,能夠實現面對面 (F2F) 或晶圓對晶圓 (WoW) 的鍵合,具有極其精細間距的直接銅對銅連接;SoIC 允許垂直堆疊不同的晶片粒,創造出一個單一、緊密整合的 3D-IC,其互連比 2.5D 封裝更短、更快;SoIC 是 A16 時代設計的關鍵賦能技術,將用於創建複雜的多功能晶片粒,然後再整合到更大的 CoWoS 封裝中;博通 (Broadcom) 成功啟動一個複雜的 3D SoIC 元件,整合了九個裸晶和六個 HBM 堆疊,這為該技術的成熟度提供了關鍵的證明。
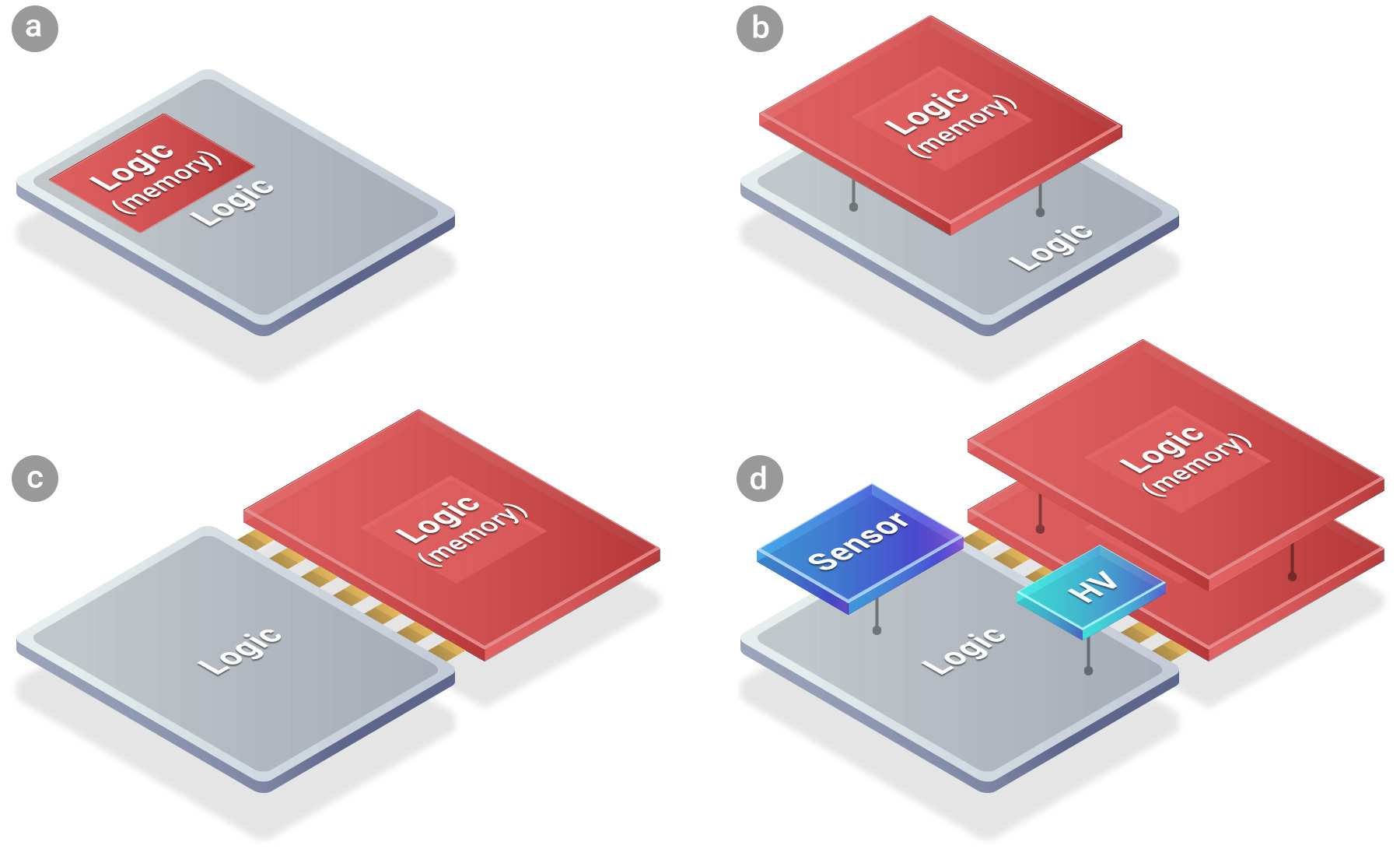
此圖展示台積電SoIC®技術實現多樣化小晶片整合的方案,圖(a)為分割前的單一系統單晶片(SoC);圖(b)與(c)則呈現了不同的整合方式,包含垂直堆疊或並排連接;圖(d)更進一步展示了其異質整合能力,能將邏輯、記憶體、感測器等多種不同功能、尺寸或製程的晶片緊密堆疊成單一晶片,是實現高效能異質整合的關鍵技術。(圖片來源: TSMC 3DFabric™ SoIC)
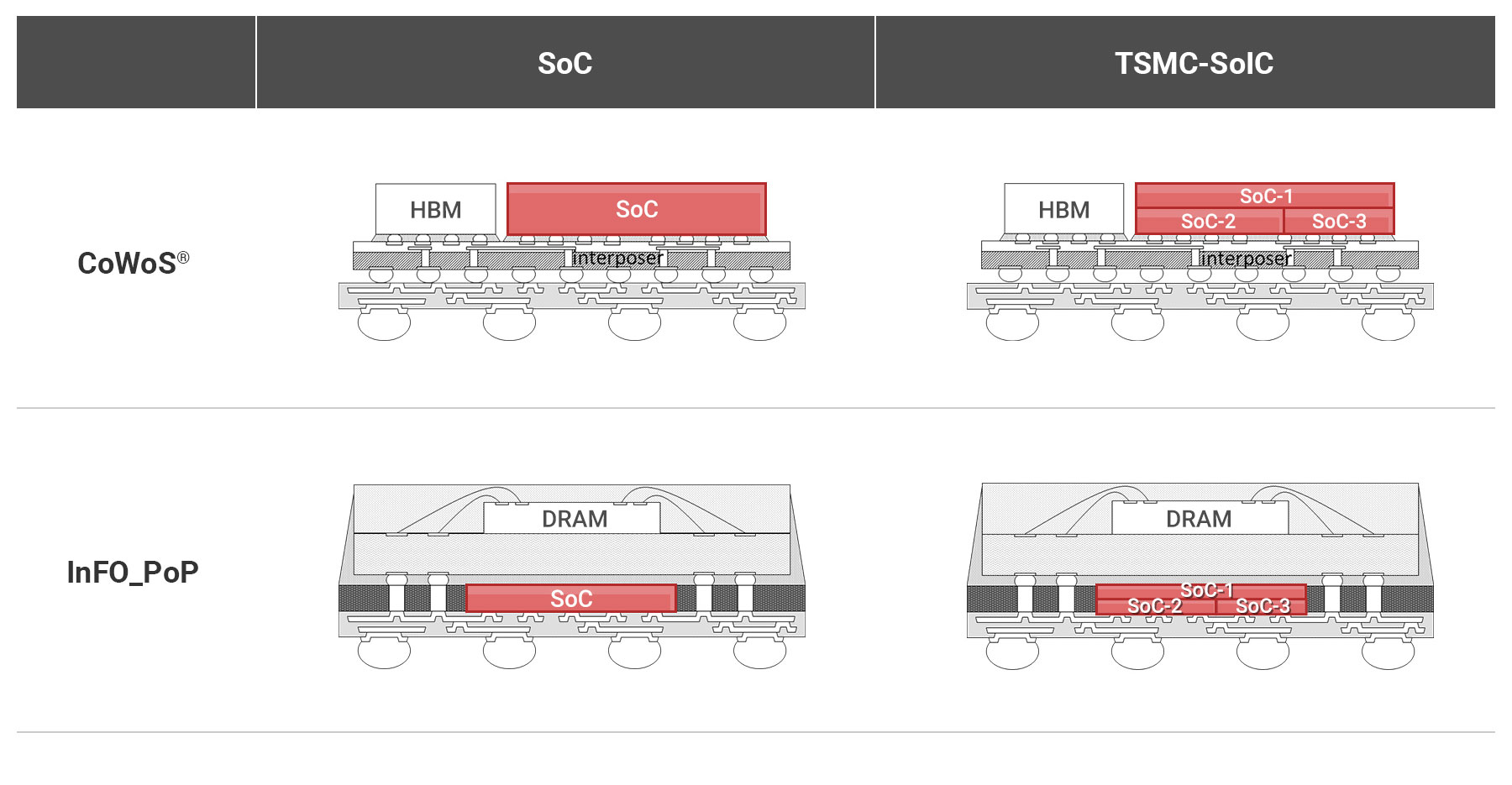
此圖比較傳統單晶片系統(SoC)與採用台積電SoIC®技術後的差異;在CoWoS®與InFO®等先進封裝中,原本單一的大型晶片(左側),可透過SoIC®技術將其分解為多個功能各異的小晶片(chiplets)再重新整合(右側);這種方法讓晶片從外觀看似單一SoC,內部卻能以更小的尺寸整合不同功能,實現更佳的效能與設計彈性。(圖片來源: TSMC 3DFabric™ SoIC)
未來是晶圓級:系統級晶圓 (SoW)
台積電最具野心的封裝願景是系統級晶圓 (System-on-Wafer, SoW)。這項技術能夠在單一 300mm 晶圓上整合大量的裸晶陣列,有效地創造出一個單一、巨大的系統,其運算能力可與整個伺服器機架相媲美;這種方法有望將每瓦效能提升數個數量級,使其成為未來超大規模資料中心的理想選擇;第一代 SoW,一個基於台積電整合型扇出 (InFO) 技術的純邏輯版本,已經在生產中;一個更先進的晶圓上晶片版本,利用 CoWoS 技術整合 HBM 和 SoIC 堆疊晶片粒,計劃於 2027 年準備就緒。
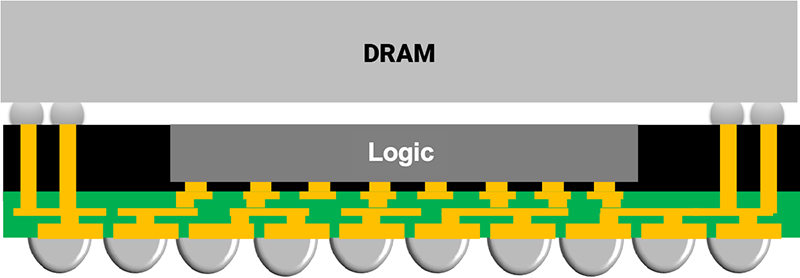
此圖為台積電 InFO-PoP (整合型扇出層疊封裝) 技術示意圖,它將上方的動態隨機存取記憶體 (DRAM) 與下方的行動應用處理器 (Logic) 整合在一起,透過高密度重佈線層 (RDL) 與整合型扇出通孔 (TIV) 的連接,InFO-PoP 無需傳統的有機基板與C4凸塊,因此能提供更佳的電氣與散熱效能,並實現更薄的封裝外形。(圖片來源: TSMC 3DFabric™ InFO)
標準化與設計賦能:3Dblox 的角色
設計這些複雜的多裸晶系統在規劃、分割和多物理場分析方面帶來了巨大的挑戰,為了解決這個問題,台積電開發了 3Dblox,這是一種開放標準的設計語言,目的在簡化 3D-IC 設計流程,它提供了一個通用的、描述性的格式,讓不同的 EDA 工具能夠在複雜的任務上無縫協作,例如:多晶片粒系統的佈局規劃、熱分析和電源完整性簽核。
至關重要的是,台積電正在將 3Dblox 提交給 IEEE 標準協會,以正式成為 IEEE P3537 標準,這是一個加速其 3D-IC 生態系統採用的策略性舉措,透過創建一個開放的、供應商中立的標準,台積電降低了整個設計社群的進入門檻,它允許 EDA 供應商建立標準化的工具,IP 供應商也能充滿信心地開發支援 3D 的 IP;雖然這對整個產業都有利,但它對擁有最先進和最全面 3D 封裝產品組合的台積電來說,益處更大;透過讓每個人更容易設計 3D 晶片,台積電確保了更多這些設計最終將在其領先的平台上製造。
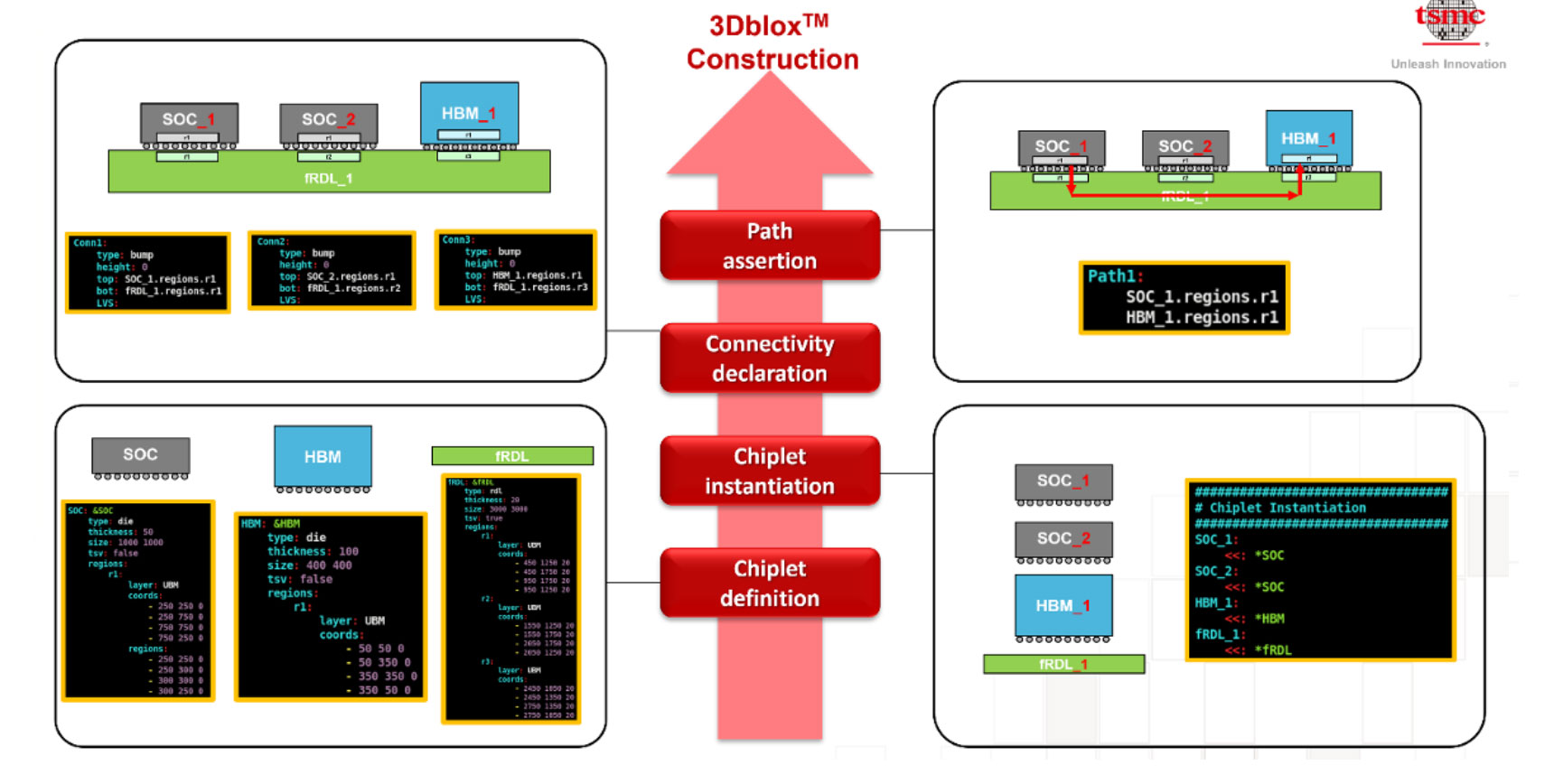
此圖展示台積電與EDA夥伴共同創建的3Dblox™設計標準,它提供一種統一的設計語言,透過標準化的流程來定義(Chiplet definition)、擺放(Chiplet instantiation)並連接(Connectivity declaration)如SOC與HBM等不同的小晶片,這簡化了複雜的3D晶片設計流程,讓客戶能更輕易地打造先進的3D整合系統。(圖片來源: 台積電部落格)
整合光:矽光子學與 COUPE
隨著晶片上處理能力的飛速增長,挑戰轉移到如何有效地將數據傳入和傳出封裝,為了解決這個 I/O 瓶頸,台積電正在開發 COUPE (緊湊型通用光子引擎),這是其共封裝光學 (CPO) 解決方案,COUPE 使用先進的混合鍵合技術,將一個電氣控制裸晶直接堆疊在一個包含矽基雷射和調變器的光子裸晶之上,這創造了一個緊湊、高頻寬、低功耗的光學引擎,台積電的藍圖計劃在 2025 年驗證 COUPE 用於可插拔光學模組,隨後在 2026 年將其完全整合到 CoWoS 封裝中,將高速光學連接直接帶到基於 A16 的運算晶片粒旁邊。
埃米時代的競技場 - 競爭格局與策略意涵
A16 的推出使台積電與其主要競爭對手英特爾和三星,在埃米時代的領導地位之爭中展開直接而激烈的競爭,每家晶圓代工廠都採取獨特的策略,在技術、時間表和風險承受能力方面存在關鍵差異,這將定義未來幾年的競爭格局。
台積電 A16 vs. 英特爾 14A
最受期待的對決是台積電的 A16 與英特爾的 14A,兩家晶圓代工廠都部署了類似的技術武器:GAA 電晶體(奈米片 vs. RibbonFET)和背面供電(超級電軌 vs. PowerVia)。
時間表
台積電已將 A16 的生產定於 2026 年下半年。英特爾則將其 14A 製程的目標時間定在 2026/2027 年,為效能和製造領導地位的直接對抗拉開序幕。
效能
誰將擁有效能桂冠的問題,是分析師之間激烈辯論的主題,一些基於公司公告的預測表明,英特爾的 18A 可能已經比台積電的 N2 略有效能優勢,英特爾希望透過 14A 擴大這一領先優勢;然而,這些都是早期的說法,最終的領導地位將取決於實際的晶片效能和製造執行力,而這正是台積電歷史上表現出色的領域。
高數值孔徑 EUV 的賭注
兩大巨頭之間最顯著的策略分歧在於他們對微影技術的態度,英特爾正大舉押注,希望成為第一個為其 14A 製程部署 ASML 新型、價格極其昂貴的高數值孔徑 (High-NA) EUV 微影機的公司,這些工具提供更高的解析度,可以簡化圖案化並提供特徵尺寸優勢;相比之下,台積電已明確表示其 A16 不需要高數值孔徑 EUV,這不僅僅是一個技術選擇,而是一個深遠的商業策略;台積電將 A16 定位為更具成本效益和風險更低的埃米節點,押注它可以使用成熟、高產能的 EUV 工具和先進的多重圖案化技術來實現其 PPA 目標;英特爾則在進行一場高風險、高回報的賭博,賭注是高數值孔徑的技術優勢將證明其巨大的成本和較低的產能是合理的;這場賭博的結果將取決於哪家晶圓代工廠能為客戶提供最具吸引力的經濟方案。
台積電 A16 vs. 三星 SF1.4
三星,作為第三大主要參與者,也正在積極追求埃米時代的藍圖,其 1.4 奈米級節點 SF1.4 計劃於 2027 年推出,也將採用 GAA 電晶體(三星品牌為 MBCFET)和 BSPDN 實作,雖然三星是第一家在 3 奈米節點引入 GAA 的公司,但普遍認為其在技術執行、製造良率和市場份額方面落後於台積電,儘管其技術雄心勃勃,三星在爭取來自領先無廠半導體客戶的大量訂單方面一直很困難,這些客戶仍然偏愛台積電久經考驗的記錄和穩健的生態系統。
客戶採用與市場動態
台積電在 2024 年第三季度據報佔有 64.9% 的晶圓代工市場份額,其主導的市場地位提供了巨大的現有優勢,這種領導地位使其能夠資助新節點的巨額研發成本,並從客戶協作和學習的良性循環中受益。
據報導 A16 已經獲得了關鍵產業領頭羊的預訂,主要客戶蘋果預計將成為其未來處理器世代的早期採用者,而 AI 領導者OpenAI 也據報透過其客製化 ASIC 開發合作夥伴,如博通和邁威爾 (Marvell),確保了 A16 的產能;這種對 HPC 和 AI 的專注是 A16 策略的核心,因為這些客戶最願意為其先進功能支付溢價。
晶圓代工廠 |
製程節點 |
電晶體架構 |
BSPDN 技術 |
High-NA EUV 採用 |
目標生產時間 |
|
台積電 |
A16 |
GAA 奈米片 |
超級電軌 (SPR) |
否 |
2026 年下半年 |
|
英特爾 |
14A |
RibbonFET (GAA) |
PowerVia |
是 |
2026 - 2027 年 |
|
三星 |
SF1.4 |
MBCFET (GAA) |
BSPDN |
未指定用於 SF1.4 |
2027 年 |
賦能未來 - 生態系統影響與設計現實
A16 的引入代表了一個轉折點,晶片設計的複雜性和成本正變得與製造一樣,成為一個巨大的挑戰;因此,A16 的成功採用,關鍵取決於整個半導體設計生態系統的共同演進,從 EDA 工具到 IP 供應商。
EDA 工具的共同演進
在 A16 製程上設計晶片需要新一代複雜的 EDA 工具,EDA 巨頭如新思科技 (Synopsys) 和益華電腦 (Cadence Design Systems) 正與台積電密切合作,開發並認證專為 A16 設計的完整數位和類比設計流程。
超級電軌的引入,使得設計軟體必須進行典範轉移。工具現在必須內在地具備 BSPDN 感知能力,整合新的功能,包括:
熱感知佈局與繞線
P&R 軟體現在必須從佈局規劃的最早階段就考慮單元放置的熱影響。
新的分析與簽核
需要全新的技術來進行時脈樹合成、跨晶圓兩側的 IR 降分析,以及考慮到改變了的熱路徑的熱簽核程序。
多物理場整合
在基於 A16 的 3D-IC 中,電氣、熱和機械應力效應的緊密耦合,使得將多物理場模擬工具(如 Ansys 的工具)整合到核心設計流程中,不僅僅是有益的,而是必不可少的。
AI 在晶片設計中的崛起
為了管理埃米級設計的驚人複雜性,台積電及其生態系統合作夥伴越來越多地轉向 AI 和機器學習。這發生在兩個方面:
AI 用於 PPA 優化
AI/ML 演算法被用來探索 A16 廣闊的設計空間,並優化 PPA 和結果品質 (QoR),這包括 AI 驅動的金屬佈線方案優化、標準單元庫配置,甚至類比電路遷移。
生成式 AI 提升生產力
大型語言模型 (LLM) 被部署來提高設計師的生產力,這些 AI 助理可以幫助生成和除錯暫存器傳輸級 (RTL) 程式碼、自動化工作流程腳本,並即時回答複雜的工具使用查詢,從而顯著加速從概念到投片的設計週期。
IP 與標準單元遷移
從 FinFET 到 GAA 的架構轉變代表現有的 IP 區塊不能簡單地移植到 A16;基礎 IP 如 SRAM 單元、標準單元庫,以及 PCIe、HBM 和 USB 等標準的複雜介面 IP 都需要完全重新設計,這對 IP 供應商和晶片設計公司來說都是一筆巨大的投資,為了降低這種轉變的風險,主要的 IP 供應商如新思科技正與台積電合作,為 N2 和 N2P 製程提供廣泛的矽驗證 IP 組合,這些預先驗證的 IP 為遷移到 A16 的客戶提供了堅實的基礎,降低了整合風險並加速了上市時間。
A16 時代設計的挑戰和成本標誌著一個關鍵的轉變,半導體進步的主要瓶頸不再僅僅在於製造廠;現在同樣在於設計公司;因此,能夠提供最全面、最穩健的設計生態系統——包括認證的 EDA 流程、AI 驅動的工具、經過驗證的 IP,以及像 3Dblox 這樣的清晰設計方法——的晶圓代工廠,將擁有決定性的競爭優勢,因為這直接解決了客戶在設計成本飆升和上市時間壓力方面最緊迫的挑戰。
結論與未來展望
台積電的 A16 技術是一項標誌性的發展,預示著埃米時代的真正開始;然而,其重要性不在於「1.6 奈米」的標籤,而在於它體現了一種新的半導體創新哲學;A16 是一個整體平台,其進步由三維架構的協同整合所驅動:環繞式閘極奈米片電晶體、超級電軌背面供電網路,以及一個系統級的 3D-IC 封裝生態系統;它標誌著從主要依賴幾何微縮,轉向一個由架構獨創性定義的未來的決定性轉變。
A16 節點及其相關技術是為滿足 AI 和 HPC 的貪婪需求而量身打造的,這是現代半導體產業的關鍵驅動力,其高昂的成本和複雜性將加速市場的兩極分化,鞏固其作為一群產業領導者開發世界上最強大處理器的首選技術地位,而廣泛的其他節點組合則服務於對成本更敏感的市場。
展望未來,台積電的藍圖持續其不懈的步伐,A14 節點,一個下一代的 GAA 製程,已經在開發中,同時也在進行超越 A14 的節點和未來電晶體結構如互補式場效電晶體 (CFET) 的探索性研發;與此同時,封裝生態系統將繼續演進,全產業向革命性的玻璃基板過渡,有望在本世紀下半葉帶來新的整合度和效能水平。
最終,A16 從根本上擴展了「製程節點」的定義,它不再是晶圓上一組離散的電晶體特性,它是一個集矽、電力架構和系統級封裝於一體的整合平台,所有這些都經過協同優化,並由一個複雜的設計工具和 IP 生態系統所賦能。透過 A16,台積電不僅僅是在建造更小的電晶體;它正在為下一個十年由 AI 驅動的創新建造基礎平台。
奧創系統半導體測試解決方案
邁向埃米時代,如 A16 這般先進製程的成功,不僅取決於微影技術的突破,更高度依賴一套完整的測試、檢測與自動化方案,以確保最高的良率與可靠性;奧創系統 (Ultrontek) 正是提供此類關鍵基礎設施的專業夥伴,其方案涵蓋了從生產到驗證的各個核心環節。
在晶圓級電性驗證上,奧創系統提供高精度的探針台 (Probe Station),作為穩定可靠的測試平台;並搭配客製化的探針卡 (Probe Card),此精密介面能同時接觸晶圓上數萬個測點,是快速篩選、分析先進製程晶片效能的關鍵。
針對 GAA 電晶體與 3D 堆疊帶來的長期可靠度挑戰,其高溫工作壽命 (HTOL) 測試方案能模擬嚴苛運作情境,而HTOL 自動化測試系統則實現了大規模、高效率的產品壽命驗證;在生產線上,為確保原子級的製造品質,自動光學檢測 (AOI) 解決方案扮演著鷹眼的角色,精準辨識奈米級缺陷以提升良率;面對 BSPDN 所需的超薄晶圓,其高效能的晶圓取放系統 (Wafer Handling)則確保了晶圓在廠內的傳送安全無虞。
這些環環相扣的半導體解決方案,共同為客戶提供了從研發到量產的強力後盾,是確保埃米級晶片成功實現的基石。
參考資料
- Gate-All-Around (GAA) Technology: Navigating Future ESD Challenges in Mass Production
- Backside Power Delivery Nears Production - Semiconductor Engineering
- TSMC drives A16, 3D process technology
- TSMC 2024 Annual Report
- TSMC 1.6nm update: Tangible improvements but new challenges emerge
- Intel's 18A node outperforms TSMC N2 and Samsung SF2 in 2nm performance class : r/hardware
- TSMC could charge up to $45,000 for 1.6nm wafers — rumors allege a 50% increase in pricing over prior-gen wafers | Tom's Hardware
- TSMC's A16 Technology Announced for Late 2026, with Super Power Rail (BSPDN)
- The Magic of Transistors: TSMC's Path to A16! (YouTube)
- 【Spotlight】Revolutionizing AI Chips: Glass Core Substrate Explained | TOKYO ELECTRON DEVICE AMERICA, INC.
- TSMC plans 1.6nm process for 2026 - eeNews Europe
- Synopsys and TSMC Usher In Angstrom-Scale Designs with Certified EDA Flows on Advanced TSMC A16 and N2P Processes
- ‘A16’ chipmaking tech to arrive in 2026, TSMC says - Taipei Times
- TSMC’s A16 Process Moves Goalposts in Tech-Leadership Game - EE Times
- TSMC, Samsung, Intel Latest Semiconductor Tech Comparison
- TSMC's cutting-edge A16 process secures orders from a "second major customer," possibly Apple or OpenAI : r/hardware
- Industry Trends: 3D Chip Stacking Technology and the Revolutionary Switch to Glass Substrates - Patently Apple
- Intel Vs. Samsung Vs. TSMC - Semiconductor Engineering
- TSMC Details N3X, Confirms N2P and A16 for 2026 - AnandTech
- TSMC Uncorks A16 With Super Power Rail - Semiconductor Engineering
- debuted the TSMC A16™ technology Archives - INO.com Trader's Blog
- 16/12nm Technology - TSMC
- TSMC Announces A16, Next-Generation Advanced Logic Technology
- How to power chips from the backside - imec
- Synopsys and TSMC Usher In Angstrom-Scale Designs with Certified EDA Flows on Advanced TSMC A16 and N2P Processes - Synopsys Newsroom
- Battle of the Titans in the Angstrom Era: TSMC’s A16 Competes with Intel’s 14A and Samsung’s SF1.4 - TrendForce
- TSMC's first 1.6nm chips with backside power coming late 2026 - The Register
- Samsung vs. TSMC vs. Intel: Who’s Winning the Foundry Market? - Patent PC
- Gate-All-Around (GAA) Transistors: Advantages & Risks - The Volt Post
- TSMC A16 Process Technology - Aminext
- TSMC's 2nm N2 process node enters production this year, A16 and N2P arriving next year - Tom's Hardware
- GAA Technology: Navigating Future ESD Challenges in Mass Production - In Compliance Magazine
- Future R&D Plans - TSMC
- The Best Kept Secret in Semiconductor Innovation: Backside Power Delivery - McKinsey Electronics
- TSMC
- TSMC to Provide 3DIC Integration for AI Chips in 2027, Featuring 12 HBM4 and Chiplets with A16 - TrendForce
- Clearing the misinformation about N2 with direct quotes from TSMC's earnings call : r/hardware
- Synopsys and TSMC Usher In Angstrom-Scale Designs with Certified EDA Flows on Advanced TSMC A16 and N2P Processes - PR Newswire
- Understanding 3D IC technology and the future of integrated circuits - Siemens Blog
- TSMC Tech Symposium 2025 - Semiconductor Engineering
- TSMC on Track for A16 Mass Production in Late 2026 with Advanced Backside Power Delivery - TrendForce
- Advancing 3D IC Design for AI Innovation - TSMC Blog
- Clash of the Foundries: TSMC, Intel, and Samsung - SemiAnalysis
- A16 Technology - TSMC
- 3Dblox™ Standard Organization
- TSMC Targets 1.6nm Process by 2026 - HardwareBee
- How is backside power really done? - SemiWiki
- TSMC announces A16 technology, paving way for 1.6nm chips by 2026 (YouTube)
- TSMC Looks Set To Hit Intel Where It Hurts, Announcing Its A16 Node With 'Super Power Rail' Backside Power Delivery - SemiWiki
- TSMC A16 3D Process - Chiplet Marketplace
- Apple's A16 Bionic processor is now being built in the States - PhoneArena
- 3D IC: The Future of Microelectronics - Number Analytics
- IEEE P3537 Archives - SemiWiki
- TSMC Details 1.4A Process Amidst Heated Rivalry With Intel - HotHardware
- TSMC says 'A16' chipmaking tech to arrive in 2026, setting up showdown with Intel - Investing.com
- TSMC 2025 Technology Symposium: A Commitment to Customers - 3D InCites
- How the CHIPS and Science Act is Fueling a U.S. Semiconductor Industry Renaissance - Synopsys Blog
- Scaling Challenges of Nanosheet Field-Effect Transistors Into Sub-2nm Nodes - ResearchGate
- TSMC’s A16 Process Moves Goalposts in Tech-Leadership Game - Design and Reuse
- 3D Integration and Stacked Wafers: The Future of ICs - Wafer World
- Short Course 1: Advanced transistor and interconnect technology for 2nm node and beyond - IEDM
- Can New Nanosheet Chip Nodes Cement TSM's Long-Term Tech Leadership? - Nasdaq
- News: TSMC says 2nm more sought after than 3nm, A16 in 2026 with backside power : r/hardware
- Review of nanosheet metrology opportunities for technology readiness - SPIE Digital Library
- Intel's 18A Node Outperforms TSMC N2 and Samsung SF2 in 2 nm Performance Class - TechPowerUp Forums
- OpenAI secures TSMC A16 capacity to produce their own AI chips : r/NVDA_Stock
- GAA Technology: Navigating Future ESD Challenges in Mass Production - University of Idaho